公開日
2025/11/20更新日
2025/12/23
はじめに
データ整形やデータウェアハウス、ETL処理といった言葉に興味を持ってはいるものの、「何から手をつければいいか分からない」という方も多いのではないでしょうか?
本記事では、数あるETL処理を行うベンダーのサービスの中でもAWS Glueに焦点を当て、その概要と具体的な手順を解説します。
AWS Glueを使用したETL処理は、Glue JobやGlue Studio、Glue DataBrewといった様々なサービスがありますが、今回はその中でもGlue Jobを使って、ETLプロセスを実施していきます。
この記事を通して、ETL処理の「準備」から「実行」、そして「結果の確認」までを実践し、Glueの各サービスへの理解を深めていただければ幸いです。
概要
きっかけ、背景
私自身が業務でAWS Glueを使用したETL処理に触れる機会がありました。
その際にAWS Glueを使用した基本的なETL処理の一貫した流れを記載した記事を見つけられませんでした。
その為、自分自身でAWS Glueを使用したハンズオンの内容を記事にしました。
目的
本記事の主な目的は、以下の2つです。
・AWS Glueの各サービスがETLのどの部分を担っているかを理解し、ETL処理の全体像を掴むこと
・ハンズオンを通して、加工前のデータがETL処理によってどのように変化するのかを実際に確認すること
記事の概要
本記事は、前編と後編の2部構成となっています。
前編の内容:
・ETL処理の概要と、それに必要なAWSサービス(AWS Glue: Crawler, Data Catalog, Job)の概要・役割の解説
・ハンズオンの目的・ゴールと手順の流れについて解説
後編の内容:
・ハンズオンの具体的な流れを把握する為の概要手順と、事前準備(S3バケット・IAMロール・生データの作成)とETL処理の実行から結果の確認までを行う詳細手順の解説
各サービスについて
ETL処理とは
ETLは、以下の3つのステップの頭文字を取ったものです。
Extract (抽出):
異なるソース(データベース、SaaSアプリケーション、ログファイル、IoTデバイスなど)から必要なデータを抽出するフェーズです。
この段階では、データの種類やフォーマットは問わず、データソースから情報を収集します。
この抽出されたデータは、多くの場合データレイクに一時的に格納されます。
データレイクは、構造化データ、非構造化データ、半構造化データなど、あらゆる種類のデータを元のフォーマットのまま大規模に保存するためのリポジトリです。
AWSでは、このデータレイクとしてAmazon S3がよく使用されます。
このように、データを加工せずに収集・保存するアプローチによって、将来的な分析要件に合わせたデータ加工や要件の変更にも対応しやすく、後続のTransformフェーズでデータを柔軟に加工することが可能になります。Transform (変換):
抽出された生データを、分析やビジネス要件に適した形式に変換するフェーズです。
これには、データのクレンジング(重複の除去、エラー値の修正)、正規化、集計、結合、フィルタリング、データ型変換などが含まれます。Load (ロード):
変換されたデータを、最終的な保存先(データウェアハウス、データレイク、BIツールなど)にロードするフェーズです。
このフェーズでは、Transformフェーズという加工プロセスを経て分析しやすいように最適化されたデータが、物理的に格納されます。
AWSサービス
ここでは、前章で解説したETL処理を実現するために、今回のハンズオンで使用するAWSサービスについて解説します。
- 2.2.1
AWS Glue
AWS Glueは、ETL処理を効率的に実行するための、サーバーレスかつフルマネージドなデータ統合サービスです。
Glueは、複雑なETLプロセスを自動化します。 - 2.2.2
Glue Crawler
Glue Crawlerは、ETL処理のExtract(抽出)フェーズにおいて、データソースのスキーマ情報を自動的に検出するために使用するサービスです。
具体的には、データソース(Amazon S3、RDS、Redshiftなど)を自動的にスキャンし、データのフォーマット、スキーマ、パーティション構造などを検出します。
このクローラが検出したメタデータは、後述するGlue Data Catalogに保存されます。
これにより、手動でスキーマを定義する手間が省け、データの変更にも自動的に対応できるため、ETLパイプラインの構築とメンテナンスが簡素化されます。 - 2.2.3
Glue Data Catalog
Glue Data Catalogは、検出されたメタデータを保存・管理するリポジトリです。
Data Catalogは、データベース、テーブル、パーティション、スキーマ情報など、データのカタログとして機能します。Glue Crawlerが作成したスキーマ情報はここに格納され、後続のGlue Jobがデータを処理する際に参照されます。
また、Amazon Athena、Redshift、Amazon EMRなど、他のAWS分析サービスもこのData Catalogを利用して、データにアクセスしクエリを実行できます。
これにより、データの探索と利用が容易になります。 - 2.2.4
Glue Job
Glue Jobは、実際のETLスクリプトを実行するサービスです。Data Catalogに登録されたメタデータを利用して、ソースデータを読み込み、変換処理を行い、最終的にターゲットのデータストア
(整形されたデータを格納するS3バケットやデータウェアハウスなど)にロードします。
Glue Jobは、Python (PySpark)またはScalaで記述されたスクリプトを実行します。
Jobはオンデマンドで実行できるほか、スケジューラー機能を利用して定期的に自動実行することも可能です。
Glue Jobは、ETLのTransformとLoadのフェーズを担う、重要なサービスとなります。
ハンズオン
概要
- 3.1.1 目的とゴール
このハンズオンは、以下の流れでAWS Glue を使用したETL処理の基本的な流れを実践し理解することを目的としています。
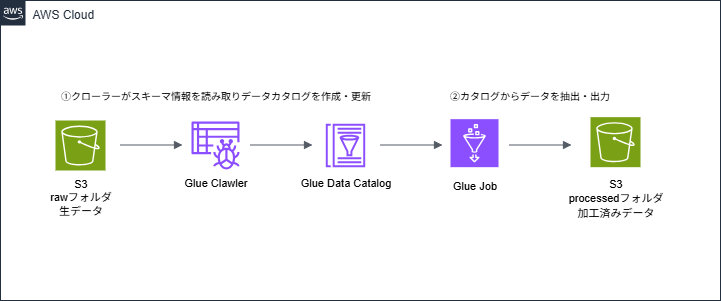
・ETL処理:S3バケットに置かれたCSV形式の生データをGlue Jobでデータ加工し(型変換)、パーティション化されたParquet形式で別のS3フォルダに保存されたことを確認
・加工済みメタデータの確認:元のデータ項目が、分析に適した形に変換されていることを確認
手順の流れ
このハンズオンは、以下の流れで進めていきます。
- 3.2.1 環境準備
1.生データとして使用するCSVファイルの作成
2.データを格納するためのS3バケットの作成 - 3.2.2 ETL処理手順
準備・設定
・作成したCSVファイルをS3バケットにアップロード
・IAMロールとポリシーの作成: ETL処理に必要な権限設定を行うExtract(抽出)
・生データ用のテーブルを作成するGlue Crawlerの実行Transform(変換)
・Glue Jobの実行Load(ロード)
・加工済みデータをS3バケットに保存出力確認
・結果の確認: S3バケットから加工済みデータが保存されていることを確認
・加工済みデータ用のテーブルを作成するGlue Crawlerの実行
・Glue Data Catalogの確認: 各フェーズで作成されたメタデータを確認
まとめ
本記事の前編では、ETL処理の概要からAWS Glueの各サービス(Glue Crawler、Glue Data Catalog、Glue Job)の役割について解説しました。
また、ハンズオンの目的とゴールや手順の流れについても解説しました。
後編では、Glue CrawlerとGlue Jobを実際に動かし、ETL処理を構築してみましょう!
下記リンクから後編の記事をご覧頂けます。
初めてでもできる!AWS GlueでETL処理を構築してみよう【後編】


 2026/04/29
2026/04/29 
 2026/04/17
2026/04/17